
1.1. ¿Qué es la inversión cuantitativa?
La inversión cuantitativa es una disciplina que aplica métodos matemáticos, estadísticos y computacionales para tomar decisiones de inversión de forma sistemática y objetiva. A diferencia de la inversión tradicional, donde el gestor evalúa empresas de forma discrecional, el enfoque cuantitativo extrae patrones de grandes volúmenes de datos históricos y construye modelos que operan de forma automática, eliminando el sesgo emocional.
En su forma más avanzada —la que se presenta aquí— los modelos cuantitativos se combinan con técnicas de inteligencia artificial para desarrollar estrategias adaptativas que aprenden del mercado de forma continua y controlada.
La estrategia B es el punto de partida, no el destino. El objetivo del club es desarrollar continuamente nuevas estrategias que se vayan sucediendo por nuevas mejores.
1.2. Ventajas y riesgos frente a la inversión tradicional
Ventajas:
- Objetividad y disciplina: El sistema ejecuta órdenes según reglas estrictas, sin influencia de sesgos cognitivos ni del miedo o la codicia.
- Velocidad y escala: Un algoritmo puede evaluar cientos de activos en milisegundos y operar con una consistencia imposible para un gestor humano.
- Backtesting riguroso: Permite evaluar el comportamiento histórico de la estrategia bajo distintos regímenes de mercado antes de arriesgar capital real.
- Escalabilidad: Una vez desarrollado y validado el algoritmo, el coste marginal de gestionar capital adicional es mínimo.
Riesgos específicos:
- Sobreajuste (overfitting): El principal riesgo en el diseño de estrategias cuantitativas es que el modelo aprenda el pasado pero no sea predictivo. Este proyecto aborda este riesgo de forma nuclear en su metodología.
- Cambio de régimen: Los mercados cambian su comportamiento. La estrategia incorpora detección y adaptación al cambio de régimen.
- Riesgo de ejecución: Diferencias entre precios simulados y precios reales de ejecución. Se mitiga operando en activos de alta liquidez (S&P 500).
- Tolerancia operativa como ventaja: A diferencia de los sistemas de alta frecuencia, «B» no es sensible a interrupciones puntuales de conectividad o a demoras en la ejecución. El sistema selecciona las mejores acciones del S&P 500 en cada momento; si un día no se opera o se opera con retraso, el único efecto es una demora en la actualización de la cartera. La siguiente mejor acción no invertida entra en sustitución de la que sale del top. Esta característica es una fortaleza del diseño frente a estrategias dependientes de la latencia.
1.3. Contexto del mercado actual para estrategias algorítmicas
El mercado global de gestión cuantitativa mueve actualmente en torno a 1,2 billones de dólares en activos bajo gestión, con una proyección de crecimiento hasta los 2,47 billones en 2032 (CAGR 8,5%). El mercado europeo de trading algorítmico alcanzó los 5.130 millones de dólares en 2024, creciendo a una tasa anual del 8,37%.
El dato más revelador sobre la dirección del sector es la adopción de inteligencia artificial: más del 80% de los hedge funds emplean ya IA en alguna forma (frente al 45% en 2020), y se estima que la IA ejecutará el 89% del volumen de trading mundial en 2025. Nos encontramos, según la taxonomía del sector, en el umbral de la denominada Quant 4.0: sistemas autónomos basados en IA, reinforcement learning y procesamiento de lenguaje natural para análisis de sentimiento.
En este contexto, una estrategia cuantitativa probada, con resultados reales verificables y una metodología sólida contra el sobreajuste representa una oportunidad de posicionamiento única. La mayoría de fondos quant institucionales requieren cientos de millones para operar. Este proyecto ofrece acceso a una tecnología de grado institucional con una estructura de capital accesible.
2. El algoritmo de inversión y el equipo
2.1. Origen y desarrollo del algoritmo
El algoritmo B es el resultado de más de seis años de investigación y desarrollo en inversión cuantitativa aplicada. Su diseño parte de un principio fundamental: evitar el sobreajuste en todas sus formas, interpretado como el uso de información del futuro en el proceso de aprendizaje o el sesgo de confirmación del autor.
La mayoría de las estrategias de inversión publicadas —tanto académicas como comerciales— son descriptivas, no predictivas: explican bien lo que ocurrió pero no predicen lo que ocurrirá. «B» rompe con esta práctica mediante una metodología rigurosa:
Principios metodológicos:
- Regresión múltiple como base: Se utiliza regresión múltiple en lugar de redes neuronales profundas como núcleo del modelo. La regresión múltiple ofrece mejor ajuste promedio, mayor interpretabilidad y menor tendencia al sobreajuste que las arquitecturas de deep learning en series temporales financieras de baja resolución.
- Procesamiento secuencial walk-forward: Los datos se procesan en modo test-forward, secuencialmente tal como ocurren los acontecimientos en el tiempo. No se usa ninguna información del futuro en ninguna etapa del entrenamiento. Esto es equivalente a simular la operativa real día a día desde el año 2016.

- Familia de estrategias: «B» no es una estrategia única sino una familia de miles de estrategias con aprendizajes y parametrizaciones distintas. Esto permite estudiar la robustez estadística del enfoque en lugar de depender de los resultados de una sola configuración. El sistema a su vez observa el mercado desde miles perspectivas distintas simultáneamente.
- Aprendizaje de cambio de régimen: Para seleccionar en cada momento cuál de las estrategias aplicar, se utiliza LEGAR (matemáticas propias), un marco matemático que mide la predecibilidad completa de un sistema —no solo el percentil superior de una simulación puntual—. LEGAR permite cuantificar cuándo el mercado es predecible y para qué tipo de estrategia. La metodología está documentada en github.com/daradija/legar.
- Parámetros ajustados solo con información pasada: Cada parámetro del modelo se recalibra periódicamente usando exclusivamente datos históricos disponibles en ese momento, evitando cualquier forma de look-ahead bias. Este proceso se complementa con una medición continua de la desviación entre el backtest y la realidad: la realidad debe mantenerse próxima o por encima del percentil 50 del backtest.
Principio estadístico fundamental — modelos no paramétricos: La metodología rechaza explícitamente el paradigma dominante de gestión de riesgos basado en matrices de varianza-covarianza (optimización media-varianza de Markowitz) y en intervalos de confianza paramétricos. El razonamiento es el siguiente: la varianza es un segundo momento estadístico sensible a los extremos de la distribución, que en los mercados financieros son frecuentes, poco predecibles y asimétricos. Fiarse de ella para construir carteras o evaluar riesgos introduce una falsa precisión.
En su lugar, el sistema trabaja exclusivamente con el primer momento (esperanza matemática) y con percentiles, ignorando los extremos de la distribución y usando técnicas no paramétricas. Esto implica aceptar que la volatilidad a escala micro no es controlable directamente —las posiciones individuales pueden oscilar con amplitud— pero sí lo es la selección de modelos predecibles mediante LEGAR y el aprendizaje de cambios de régimen. El resultado backtest es una estrategia con volatilidad elevada en el corto plazo y rentabilidad excepcional en el largo plazo, una combinación que la gestión tradicional basada en varianza nunca capturaría correctamente.
- Diversidad de perspectivas mediante aleatoriedad controlada: Cada una de las miles de estrategias de la familia B aprende del mercado desde un ángulo distinto, con distintas semillas aleatorias y distintos subconjuntos de datos. Es como tener miles de analistas independientes que observan el mismo mercado y llegan a conclusiones diferentes. Ninguno tiene razón absoluta, pero el conjunto captura una imagen del mercado mucho más completa y robusta que cualquier estrategia única.
- Álgebra de estrategias — actuar solo con expectativa de lucro: De las miles de estrategias, en cada momento solo operan aquellas que tienen expectativa matemática positiva en el régimen de mercado actual. La media del conjunto no es suficiente: se identifican pequeños grupos de estrategias con expectativa de rentabilidad especialmente alta y se les da mayor peso. LEGAR actúa aquí como brújula: es un estimador insesgado que mide si una estrategia tiene verdadera predecibilidad o si su rendimiento pasado es ruido. Permite ahorrar recursos descartando estrategias sin predecibilidad real antes de invertir en desarrollarlas.
Estudio Margin Call hecho sobre B2d – 160% apalancamiento
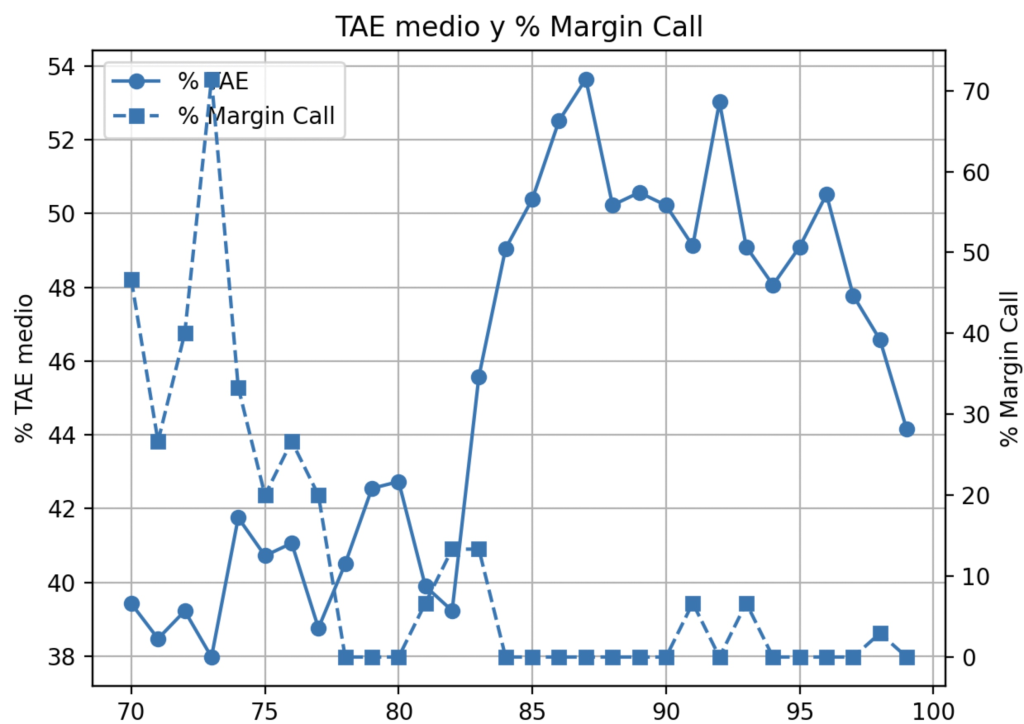
Estrategia B2, efecto en el TAE al operar algebra de estrategias, en el percentil 90 se produce una subida del TAE.
Operativa de B2:
La estrategia B2 opera en el mercado de renta variable norteamericano (S&P 500) con las siguientes características:
- Universo de inversión: Las 500 mayores empresas por capitalización del índice S&P 500.
- Tamaño de cartera: 10 posiciones simultáneas (predeterminado).
- Rotación: Aproximadamente 3 posiciones diarias (3 compras y 3 ventas), con baja fricción por operarse en valores de alta liquidez y con ordenes límites y no a mercado, lo que mejora la fiabilidad de la simulación con respecto a la realidad.
- Filtro de masa monetaria (M2): Mide la aceleración de creación de masa monetaria, una vez cae sobre cierto percentil, sale de mercado para prevenir caídas relativas a la falta de dinero en circulación.
- Bróker predeterminado: Interactive Brokers, con acceso directo a mercado y comisiones de grado institucional.
- Horizonte temporal: Intradía extendido / swing (posiciones de días a semanas).
- Se ejecuta una vez al día, y el sistema completo -> estrategia + código abierto, crearía y cargaría las señales como órdenes límite si procede.
El sistema de ejecución es completamente automatizado si se quiere, ya que existe la opción manual para operar con cualquier bróker. Las órdenes se generan de forma local y se transmiten directamente al bróker IB mediante su API. Se hace la carga una vez al día, pero hay formas de automatización para que funcione a lo largo de una semana completa.
2.2. Rentabilidades históricas y pruebas (backtesting)
Aquí tienes un análisis de 200 simulaciones de la estrategia B2d, obteniendo una distribución estadísticamente representativa de los resultados con inicialización aleatoria.
Estos datos son públicos y se encuentran en nuestro repositorio de código abierto.
Distribución de TAE — Backtest B2d
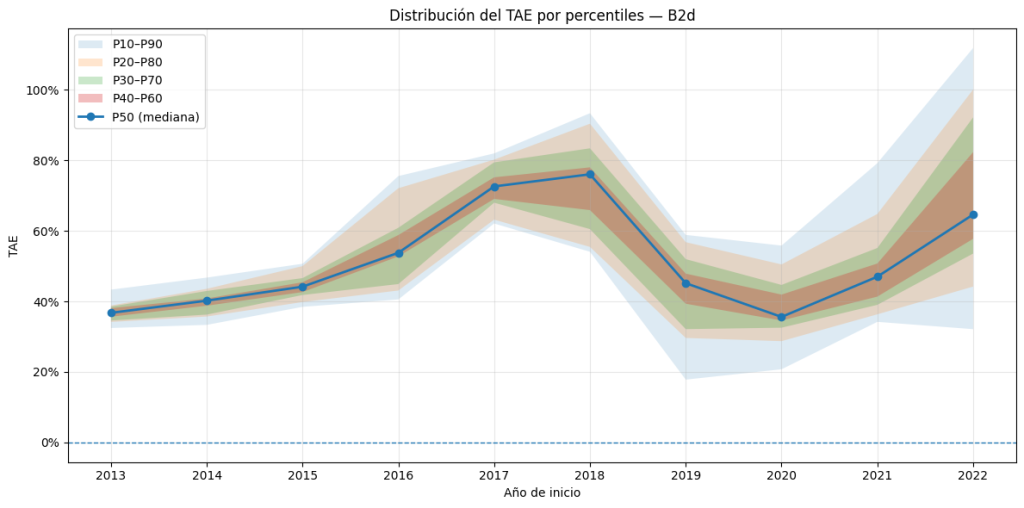
El análisis de la distribución de rentabilidades anualizadas (TAE) muestra una franja central claramente positiva, teniendo en cuenta que no se aplica el filtro de masa monetaria sobre M2 para años anteriores a 2018. Tomando como referencia los percentiles 10 y 90 de la muestra, los resultados son los siguientes:
| Métrica | Valor |
|---|---|
| TAE mínima observada | +7,8% |
| TAE percentil 10 (P10) | +32,0% |
| TAE mediana (P50) | +45,9% |
| TAE medio | +51,3% |
| TAE percentil 90 (P90) | +80,2% |
| TAE máxima observada | +150,3% |
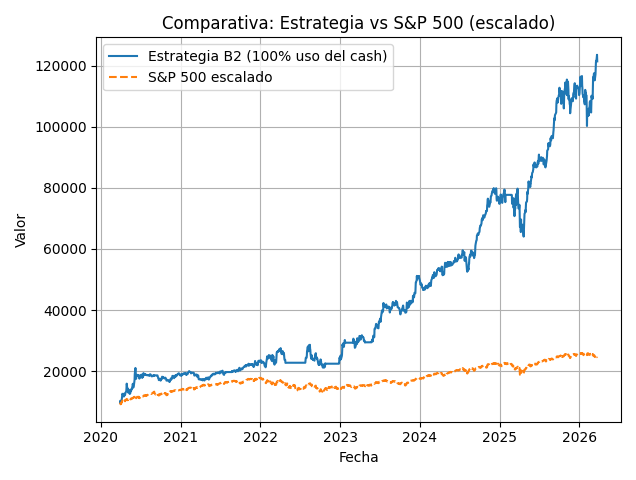
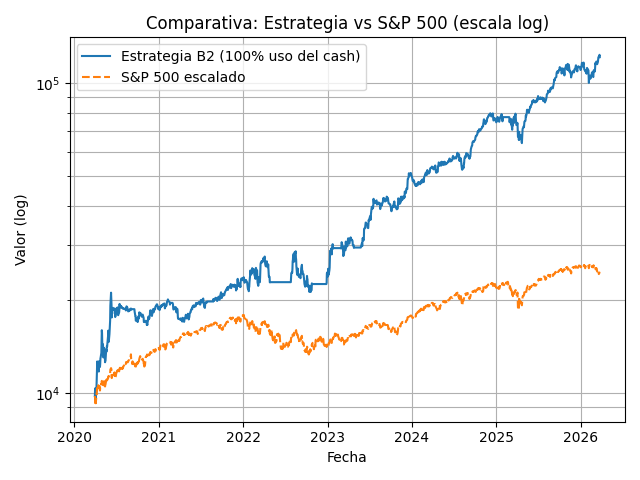
2.3 Ejemplos de gráficos backtest
Los siguientes gráficos son simulaciones para dos estrategias B cualesquiera dentro de la misma familia B, en concreto de la versión última, la B2d.
B2d – 100% uso de cash (sin apalancar)
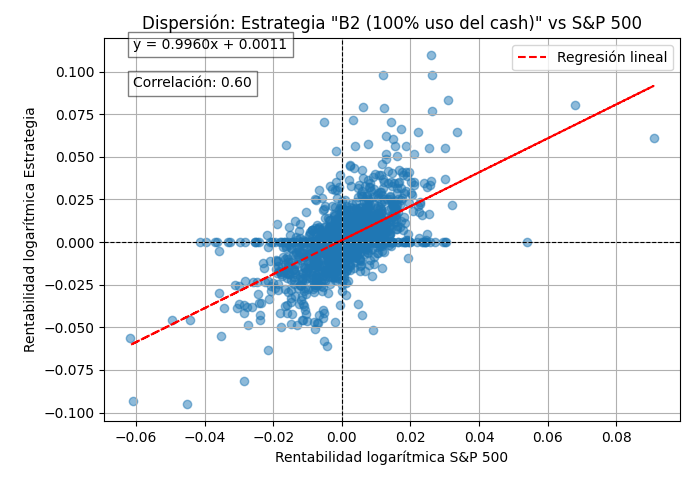
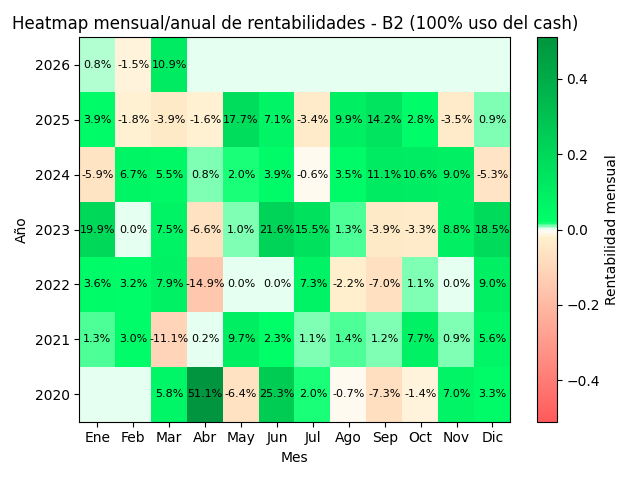
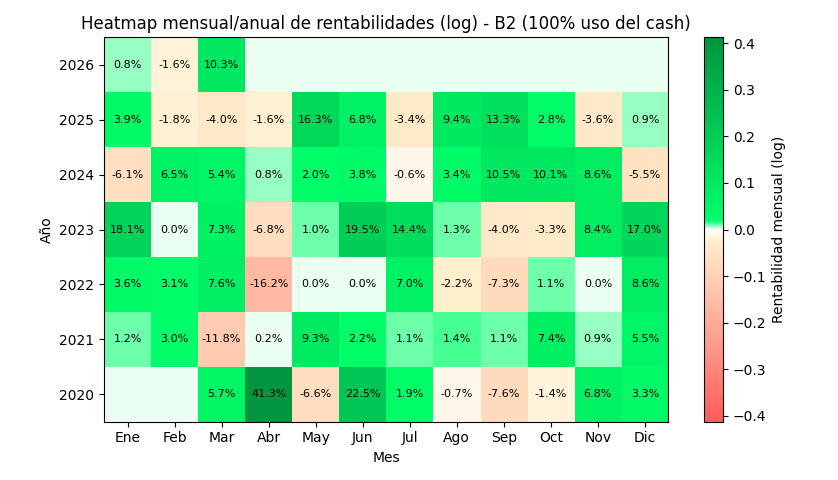
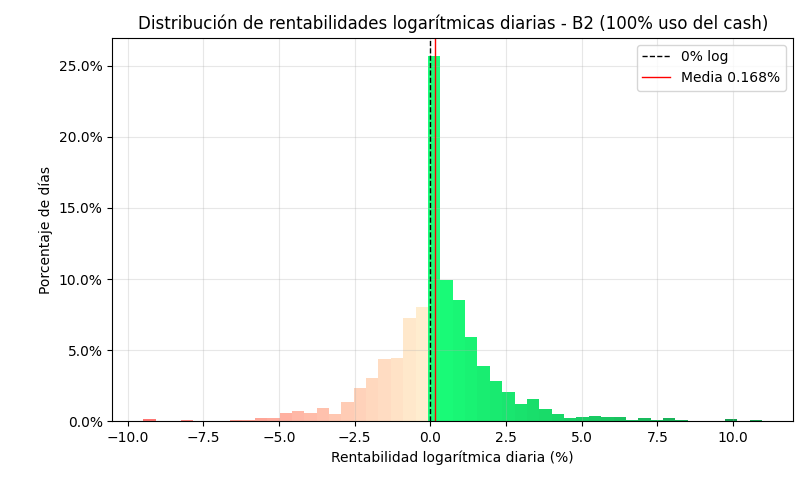
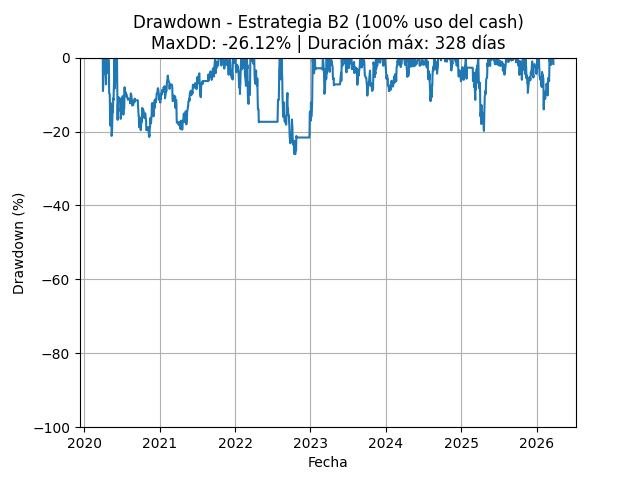
B2d – 160% uso de cash (apalancada)
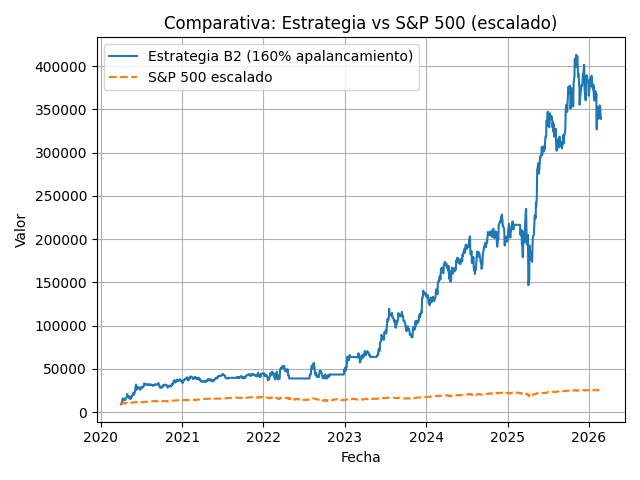
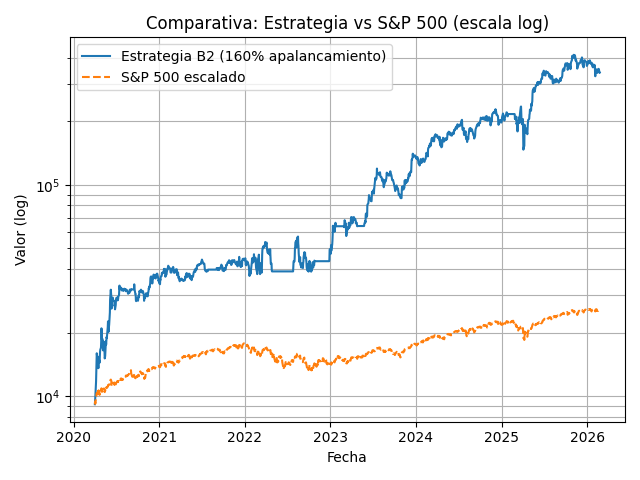
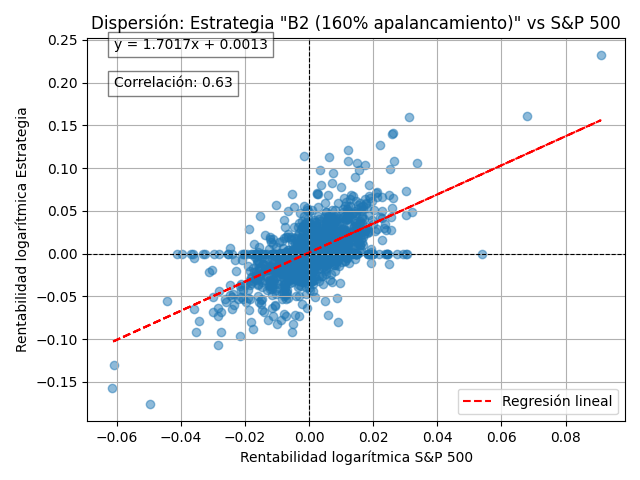
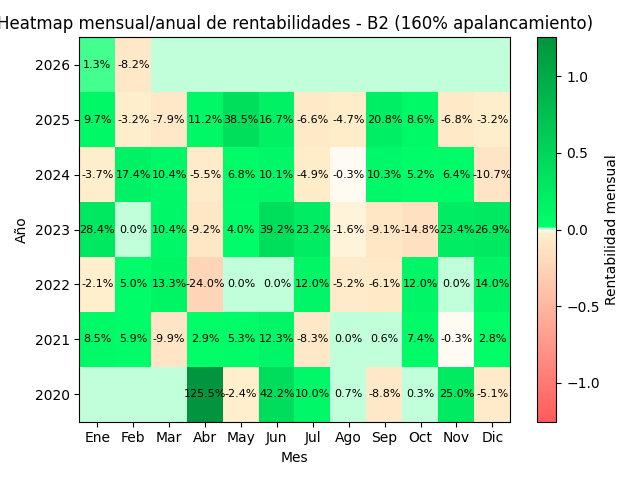
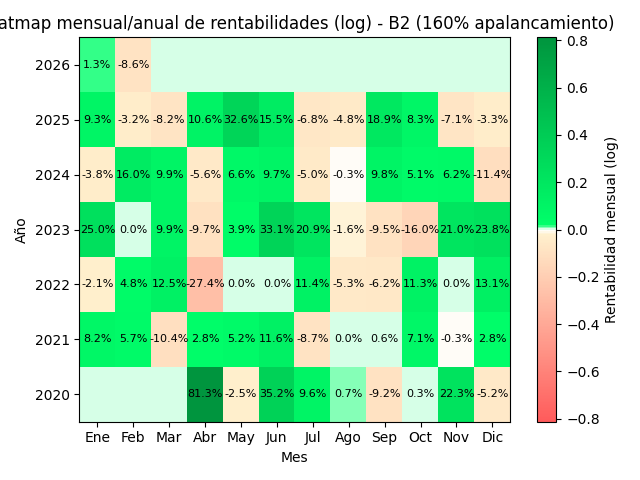
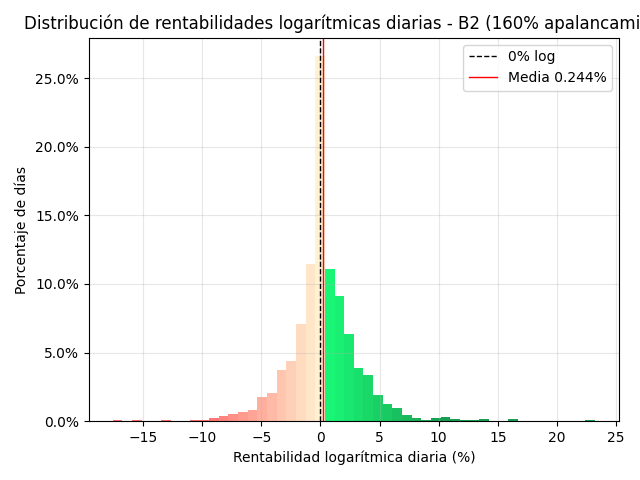
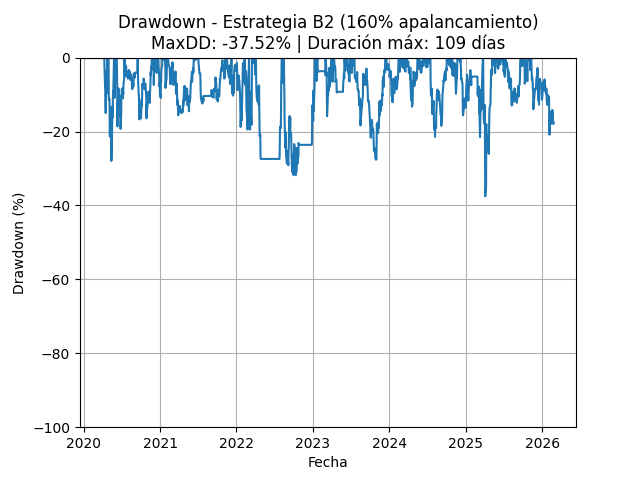
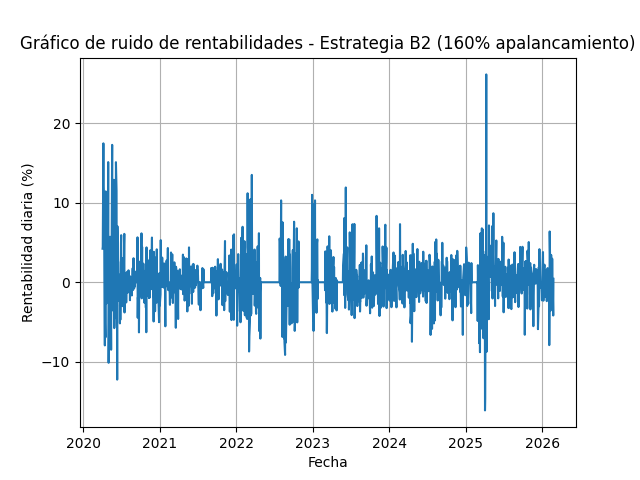
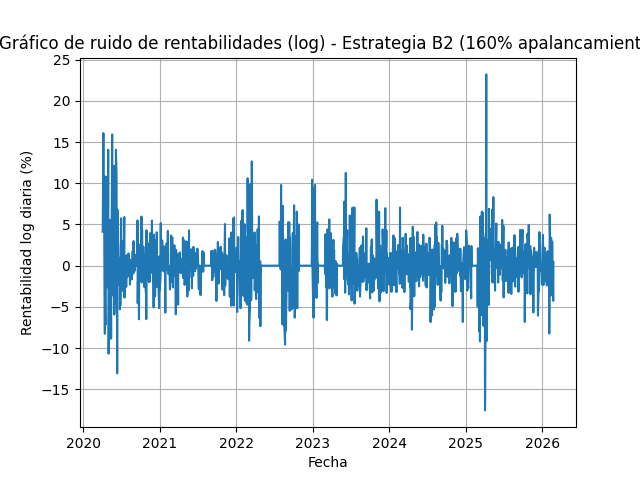
El sistema permite simular para así luego poder medir tu desviación realidad vs simulación. El tipo de modelo que usa tiene reproducibilidad, por lo que lo hace muy interesante para comparar tu operativa con los backtest que generes.
La estrategia se ejecuta en nuestro clúster, la parte de la operativa es pública y mantenida por al comunidad. Esto lo hace muy interesante, ya que si sabes programar puedes adaptar la parte de la operativa a tu gusto, mientras la parte privada (la parte heurística) permanece intacta.
2.4 Historia y historial de versiones
La nomenclatura que se usa de letra-numero-letra-etc sirve para que las subversiones no se pisen. La primera letra hace alusión a la familia de estrategias, la segunda parte (número) hace alusión a subversiones de mejora, y la tercera letra a arreglos / mejoras.
Se empezó inicialmente con la familia de estrategias A, la cuál tuvo mucho adopción y mucho éxito, y por ello se creó el club.
Seguidamente se creó la familia B, que posee el filtro de masa monetaria y hace uso de memoria (a diferencia de A). Su primera versión fue la B1, que no se publicó ni se uso en el club, ya que usaba demasiados recursos de cómputo y tardaba muchas horas en ejecutarse.
Esta versión se consiguió optimizar tras varios meses y dio lugar a la B2, que esta si se adecuaba a los requisitos necesarios para ofrecerla. Se hizo una serie de mejoras a nivel de entrenamiento para suavizar caídas y ofrecer unos resultados backtest más estables que dieron lugar a la versión B2d.
La siguiente versión que se espera es la B3, la diferencia principal radicaría en cuestiones de ejecución, en que parte del open source se pasaría a la parte privada y esta funcionaría por nuestro sistema shell, así la ejecución sería más rápida y los datos se mantendrían limpios para todos de forma centralizada.
¿Te gustaría probarla?
Descubre nuestros itinerarios y opta a acceder a nuestra comunidad.